
Hvor træfsikker er en model der forudsiger udfald af fodboldkampe på baggrund af hold- og spillerstatistik fra Opta? Kan man tjene penge på det? Og kan en sådan model profit-optimeres når man kobler klassiske value-principper på den?
Som spiller hos bookmakerne går man sjældent af vejen for at bruge værktøjer der kan lette lidt af det hårde benarbejde når de bedste spil skal findes. Man kan kigge i stillinger og statistikker og forsøge at dechiffrere tallene - eller man kan forsøge at få maskiner og software til at gøre arbejdet for sig.
Vi har testet en interessant "Prediction Model", som er en software-model der hævder at kunne forudsige udfald af kampe i den engelske Premier League. Vi undersøger om modellen kan lave profit, og tager den yderligere et skridt videre og underlægger den principperne om valuebetting.
Baggrund
På det engelske website EPLindex.com er de glade for tal og statistikker. Rigtig glade. Deres ultimative fokus er, som navnet antyder, den engelske Premier League, og en horde af skribenter publicerer hver uge et hav af artikler hvor de små facetter i spillet vendes og drejes.
EPLindex har en skribent der går under synonymet datamonkey, og han har gennem knap 20 spillerunder i denne sæsons Premier League kørt et projekt han kalder "EPL Prediction Model". Modellen, der er udviklet over nogle sæsoner, er baseret på Opta's statistikker for hold og spillere i Premier League.
Ud fra forventede startopstillinger returnerer modellen - på baggrund af et stort antal simuleringer af hver enkelt kamp - en chancefordeling for kampenes udfald. Dermed ligner modellen til forveksling "motoren" fra diverse managerspil, som fx Football Manager, dog med den væsentlige forskel at den bygger på reelle spiller-præstationer.
Modellens store styrke ligger i dens udgangspunkt i faktiske statistikker for de hold og spillere der er i kamp. Modsat mange andre rating-modeller skeler den ikke så meget til holdenes form, hjemme/udebanestyrke, angstmodstandere, dommere, osv. I stedet fokuseres på mere konkrete statistikker som fx holdenes boldbesiddelse, afleveringsprocenter, hvor træfsikker den enkelte spiller er med pasninger, indlæg og afslutninger, hvor ofte en spiller begår fejl, frispark osv.
Gennem simulation giver modellen et fingerpeg om sandsynligheden for at kommende kampe ender med hjemmesejr, uafgjort eller udesejr. Gennem Premier League sæsonen 2013/14 har datamonkey anlagt en lille, ikke synderligt videnskabelig betting-vinkel på modellen, og simuleret at modellen placerer spil hos en bookmaker (i hans fiktive eksempel altid hos Bet365*). Dette sker uden skelen til grundlæggende value-begreber, som modellen altså ikke har nogen holdning til.
Via modellen har datamonkey i sine fiktive spil fulgt denne devise: spil på uafgjort hvis modellen giver 27% chance eller mere for dette udfald[1] - ellers spil på det hold modellen siger har størst sandsynlighed for at vinde kampen. Vel at mærke uagtet om odds på det pågældende udfald er højt eller lavt.
Dette medfører på den ene side at man aldrig behøver tænke sig om, men på den anden side betyder det også at man nogle gange havner i situationer hvor man skal spille til odds 1,15 på et udfald som modellen måske kun tildeler 40% chance for. Men som sagt: modellen kender ikke til value-begrebet.
Chancevurdering er vejen til profit
Modellen er som sådan ikke udviklet med betting for øje, men kan man så bruge den til det? En model som kan forudsige ikke bare de mest sandsynlige udfald, men også tildele procenter for de mulige udfald må vel være en sand guldgrube i hænderne på en spiller som kan bruge modellen til netop betting?
Muligvis, men først må vi se lidt nærmere på den ultimative præmis for modellen: chancevurderingen.
Her på BetXpert er chancevurderingen et af de helt centrale begreber i vores spilforslag. Det er det værktøj der fortæller om man har en fordel i forhold til de odds bookmakerne tilbyder, netop fordi produktet af chance og odds er lig med betvalue - den teoretiske værdi for det pågældende spil.
Ofte er chancevurderinger omgærdet af kontroverser, da det (endnu) aldrig er lykkedes nogen at opstille en konkret og eviggyldig formel som kan udtrykke en "sandfærdig" chancevurdering for en given kamp eller begivenhed.
Der er så mange faktorer at tage højde for, både objektive og subjektive, at det nok aldrig lader sig gøre at opstille denne eviggyldige formel. Der er simpelthen for meget at tage højde for. Form og holdenes indbyrdes styrke er nogle af de faktorer som de fleste almindeligvis kan forholde sig til, men især når vi bevæger os ned i de små marginaler, som ofte kan afgøre om betvalue er til stede eller ej, bliver det svært:
- Hvordan påvirker vejret et udehold i en norsk Tippeliga-kamp i Tromsø midt i april?
- Hvordan påvirker det et NHL-hold når de skal spille 6. udekamp i træk i et 10-dages road trip?
- Hvordan præsterer Randers FC når de spiller fredag aften i forhold til søndag eftermiddag?
- Hvordan påvirkes Chelsea's sejrs-chance i en hjemmekamp mod Arsenal hvis de stiller op med Demba Ba i stedet for Fernando Torres?
- Osv.
En masse af sådanne faktorer kan og vil påvirke chancevurderingen for enhver kamp. De virkelig dygtige spillere bruger som regel deres enorme indsigt og erfaring til at danne sig et indtryk af hvor meget de forskellige forhold påvirker chancerne for en given kamp. De har så at sige en formel i hovedet, dog uden at kende dens konkrete opbygning, men ud fra denne ved de i store træk hvor meget de forskellige faktorer hver især spiller ind.
En dygtig spiller formår at destillere denne viden ud i tal som ofte rammer plet når man sammenholder betvalue (den teoretiske værdi) med hans reelle tilbagebetaling (den faktisk værdi).
Den helt store forskel på den foreliggende model fra EPLindex og mange af de andre rating-modeller der er tilgængelige, og netop det der gør denne model interessant, er dens afsæt i Opta statistikker. Den kan nemlig give et tilnærmelsesvist svar på flere af de marginale variable, bl.a. et af de spørgsmål vi stillede herover: hvordan det påvirker et holds chancer hvis de udskifter én spiller med en anden i startopstillingen.
I et eksempel som datamonkey har givet på sin personlige blog, beregnede han chancerne for opgøret Chelsea-Arsenal i sæsonen 2012/13 til at være 44-30-26 ud fra en forventet opstilling med Fernando Torres i front for Chelsea. Hvis man erstatter Torres med Demba Ba i Chelsea's opstilling ændrer procenterne sig til 46-27-27.
Chelsea's sejrschance øges altså med 2%, men Arsenal's sejrschance er faktisk også steget (på bekostning af X'et). Hvorfor? Fordi Demba Ba's Opta statistik for 2012/13 fortæller modellen at han er mere træfsikker end Torres, men bl.a. også er mere tilbøjelig til at afgive boldbesiddelse, hvorfor Arsenal's sejrchancer også øges.
Nok om teorien - lad os se hvordan EPLindex modellen har klaret sig på betting-fronten i denne sæson.
Godkendt tilbagebetaling på primitive vilkår
Selvom modellens devise for hvordan man skal placere sine spil strider åbenlyst mod alle de begreber vi som regel hylder her på BetXpert, så lad os antage at vi gennem Premier League sæsonen 2013/14 har fulgt EPLindex' spillestrategi blindt (spil på X ved 27%+ chance herfor, ellers på holdet med størst sandsynlighed) på alle de tip der er anvist, og har fået gennemsnitligt markedsodds på alle udfald.
De første tip til sæsonen kom først ud til 9. spillerunde, og med 28. spillerunde delvist afviklet i den forgangne weekend, er der knap 200 kampe at vurdere på:
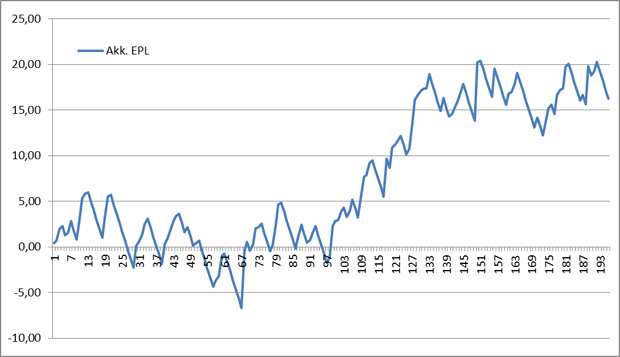
Figuren viser udviklingen i akkumuleret profit hvis man havde spillet 1 unit på samtlige de udfald modellen foreslog. Med to aflyste kampe i runde 26, giver det en total på 196 kampe.
Modellen har ramt rigtigt udfald i halvdelen af kampene (98) og holder dermed en hitrate på præcis 50%. Overskuddet efter 196 spil er på 16,29 units, hvilket giver en pæn tilbagebetaling på 108,31%.
Valuebetting FTW – eller hvad?
Som det sig hør og bør her i BetXpert-universet, rører vi som regel ikke værdiløse spil med en ildtang, så vi vil selvfølgelig nu lægge betvalue-princippet ned over EPL-modellen. Vi har EPL-modellens procentvise sandsynligheder for samtlige kampe ved hånden, og tager udgangspunkt i de gennemsnitlige markedsodds for alle kampene.
Devisen er enkel: I hver enkelt kamp spiller vi det udfald der giver den højeste betvalue. Er der ingen udfald med value på 100 eller over, afstår vi fra spil på kampen.
Lad os se hvordan den akkumulerede profit ud fra Betvalue princippet (rød kurve) tager sig ud overfor EPL-modellens akkumulerede profit (blå kurve):
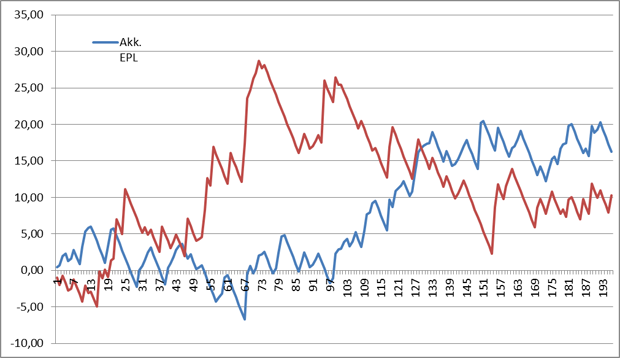
Kun en enkelt kamp havde en betvalue under 100 på alle udfald, og derfor har betvalue-princippet anvist 195 spil. Med en indsats på 1 unit pr. spil ville vi stå tilbage med en profit på 10,28 units, svarende til en tilbagebetaling på 105,27%.
Bestemt godkendt, men vejen til denne profit er markant anderledes end via EPL-modellen, hvilket især afspejles af hitraten. Med udgangspunkt i betvalue-princippet lander den på magre 32,8% og har altså en langt dårligere træfsikkerhed end EPL-modellen.
Hvorfor så store forskelle i hitrates og saldo-udvikling?
Selvom de to kurver herover har steder hvor de følges pænt ad og efter knap 200 spil begge lander på tilnærmelsesvist samme tilbagebetaling, så er der enorme forskelle undervejs, grænsende til det betænkelige.
Kigger vi nærmere på dataene viser det sig at betvalue-princippet i langt højere grad end EPL-modellen anviser spil på underdogs. Et par eksempler fra sæsonen illustrerer dette:
| Kamp | EPLindex CV | Odds | EPL profit | BV profit |
| Tottenham-Newcastle | 43 - 22 - 35 | 1,53 - 4,10 - 6,39 | -1,00 | +5,39 |
| Sunderland-Manchester City | 19 - 22 - 60 | 7,18 - 5,43 - 1,44 | -1,00 | +6,18 |
EPL-modellen anviser spil på Tottenham og Man City fordi de har størst chance for at vinde, men i ingen af tilfældene er der tilnærmelsesvist tale om valuebets (betvalues på de to spil er hhv. 65,79 og 86,40). Ud fra betvalue-princippet skal man i stedet spille stik modsat, da oddsene på Newcastle og Sunderland giver massive betvalues på 223,65 hhv. 136,42.
I disse to tilfælde pegede spillene altså i hver sin retning, og hvor EPL-modellen gav 2 tabte units, hentede vi hele 11,57 units i overskud med betvalue-modellen, fordi begge underdogs vandt.
Når vi gennemgår data for samtlige 196 afviklede kampe, kan vi se dette mønster gentage sig: det gennemsnitlige odds der anbefales ud fra betvalue-princippet er helt oppe på 4,90 mens det for EPL-modellen er 2,56.
Der er altså en relativt stor skævhed i retning mod underdog-favorisering når man benytter betvalue-modellen. Eller, sagt med andre ord: EPL-modellen tildeler sjældent favoritterne tilstrækkelig stor favoritværdighed i forhold til gældende markedsodds, og derfor vil betvalue-princippet sjældent finde værdi på favoritterne.
Dette er en klar udfordring for modellen, som vi evt. vil kigge nærmere på når den har kørt i lidt længere tid og indsamlet mere evidens i form af kampe og resultater.
Konklusioner – virker modellen?
Modellen kræver noget tilpasning før den egner sig til betting. Ovenstående gennemgang viste sig at EPL-modellen giver overskud uanset om man slavisk følger modellens egen anvisning eller anlægger et betvalue-princip. For begge metoders vedkommende virker overskuddet dog ret skrøbeligt - for betvalue-princippets vedkommende ville der have været underskud hvis blot 2 af de 195 spil var endt med anderledes udfald, nemlig spillene i de 2 kampe nævnt ovenfor (Tottenham-Newcastle og Sunderland-Manchester City).
Det skal være usagt hvordan modellen vil præstere på længere sigt, men som udgangspunkt er den interessant fordi den meget konkret anskuer noget som sjældent inkluderes i simuleringer; spillernes individuelle egenskaber/præstationer.
EPLindex-modellen er stadig ung, og har slet ikke akkumuleret en tilstrækkelig mængde data til at det er forsvarligt at lade den danne grundlag for sine spil. Dertil er dens præmis for at forudsige kampenes udfald også for tyndt og uvidenskabeligt i forhold både til sund money management og til grundprincipperne om valuebetting, og hvis den skal danne grundlag for betting (med value) skal den tilpasses på visse områder, især i dens over-favorisering af underdogs.
Som retningsviser virker modellen brugbar, især fordi den trods alt har været i stand til at forudsige korrekt udfald i 50% af 196 Premier League kampe. Skal man tage modellen et skridt videre i betting-sammenhæng, gælder det dog om at finde den ”nøgle” der skal til for at få modellen til også at indtænke principper for netop money management og valuebetting.
Hvad kan forbedres?
Vi har i vores gennemgang af modellen identificeret yderligere parametre, som begrænser modellen, og som den med fordel kan videreudvikles/forbedres på:
- Forventede startopstillinger contra faktisk opstillinger
På EPLindex er forslagene udelukkende givet med udgangspunkt i forventede startopstillinger. Hvis man ventede med at sætte sit spil til de faktisk startopstillinger var offentliggjort, ville modellen sandsynligvis kunne præstere marginalt bedre. - Startopstillinger er ikke den fulde sandhed
Modellen tager ikke højde for ind-/udskiftninger undervejs i kampene, hvilket i og for sig er naturligt nok, da man meget sjældent kan forudsige hvornår et hold foretager disse, eller hvilke spillere der skiftes ud og ind. I et eller andet omfang bør det dog altid spille ind hvor stærk en udskiftningsbænk et givet hold har, da det vil påvirke en kamps forløb fra det øjeblik den første indskiftning foretages. - Kun fokus på Premier League
Holdene i Premier League spiller også kampe i andre turneringer, hvor Opta data ikke indsamles. Endvidere kan modellen ikke bruges når et hold får tilgang af en ny spiller, hvis tidligere præstationer ikke er tracket af Opta, som fx når Chelsea køber Nemanja Matic. Modellen kender ikke den potentielle betydning af en spiller før den har data på ham. Samme begrænsning opstår i forhold til oprykkerhold i starten af sæsonen, hvor modellen ikke har Opta statistikker på disse. - Der anbefales spil på samtlige kampe
Modellen anviser inden begrænsninger mht hvilke kampe man bør/ikke bør spille på. Uanset om der er tale om en kamp hvor bookmakernes odds indikerer at vi har et gøre med en formodet storfavorit og en stor underdog, eller om det er et meget tæt opgør, så anviser procenterne slavisk hvilket udfald man skal spille på – hver gang. - Modellen er for snæver
De fleste rating-modeller udviklet med betting for øje er for snævre i deres betragtningsvinkel, da de hver især kun tager få parametre med i anskuelsen, fx ved udelukkende at kigge på holdenes "scorings-overlegenhed" (goal supremacy). Samme kritik kan rejses mod EPL-modellen, om end den faktisk anskuer nogle parametre som mange andre modeller forsømmer, nemlig spillerne. En sammensmeltning af flere af de tilgængelige modeller, som hver især kan understøtte hinandens svagheder og mangler, burde i sig selv være mere retvisende.
Leg selv videre
For de brugere der har lyst til at lege videre med modellen, har vi gjort de data der ligger til grund for denne artikel tilgængelige i et Excel-ark her. Filen kan frit benyttes privat.
Kan man finde en gylden middelvej hvor man kombinerer de to modeller/principper og dermed maksimere profitten på EPL-modellen og samtidig minimere de store og relativt risikobetonede udsving på den strategi der følger betvalue-princippet? Værsgo at gøre et forsøg!
Selvom ophavsmanden til modellen flere gange har erklæret at han ikke har udviklet modellen med betting for øje, så tillader vi os alligevel at give betragtningerne fra denne artikel videre til ham. Og hvis nogen blandt brugerne finder på yderligere at tilføje ved selv at grave i tallene, så lad endelig høre fra jer!
Vil du vide mere?
Fuld baggrunds-info om EPLindex modellen kan findes på denne blog. Her har datamonkey, under sit borgerlige navn Neil Charles, beskrevet modellen fra dens spæde start og frem til nu.
Hver fredag poster datamonkey modellens forudsigelser til Premier League på http://www.eplindex.com.
Opta, som indsamler data på stort set ethvert skridt der tages på banerne i Premier League, kan besøges på http://www.optasports.com (eller følges på en af firmaets mange Twitter-profiler).
_____________________________________
Fodnoter
[1] Frem til spillerunde 20 var grænsen for uafgjort sat til 25%, men denne grænse blev justeret op til 27% for at imødekomme at der blev scoret færre mål i ligaen end oprindeligt projekteret, hvilket implicit øger chancen for uafgjorte kampe.









